24.8 Relationships (n-grams)
library(dplyr)
library(tidytext)
library(janeaustenr)
austen_bigrams <- austen_books() %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2)
austen_bigrams
## # A tibble: 725,049 x 2
## book bigram
## <fct> <chr>
## 1 Sense & Sensibility sense and
## 2 Sense & Sensibility and sensibility
## 3 Sense & Sensibility sensibility by
## 4 Sense & Sensibility by jane
## 5 Sense & Sensibility jane austen
## 6 Sense & Sensibility austen 1811
## 7 Sense & Sensibility 1811 chapter
## 8 Sense & Sensibility chapter 1
## 9 Sense & Sensibility 1 the
## 10 Sense & Sensibility the family
## # ... with 725,039 more rowsausten_bigrams %>%
count(bigram, sort = TRUE)
## # A tibble: 211,236 x 2
## bigram n
## <chr> <int>
## 1 of the 3017
## 2 to be 2787
## 3 in the 2368
## 4 it was 1781
## 5 i am 1545
## 6 she had 1472
## 7 of her 1445
## 8 to the 1387
## 9 she was 1377
## 10 had been 1299
## # ... with 211,226 more rowsRemove stop words and get new counts
library(tidyr)
##
## Attaching package: 'tidyr'
## The following object is masked from 'package:magrittr':
##
## extract
bigrams_separated <- austen_bigrams %>%
separate(bigram, c("word1", "word2"), sep = " ")
bigrams_filtered <- bigrams_separated %>%
filter(!word1 %in% stop_words$word) %>%
filter(!word2 %in% stop_words$word)
# new bigram counts:
bigram_counts <- bigrams_filtered %>%
count(word1, word2, sort = TRUE)
bigram_counts
## # A tibble: 33,421 x 3
## word1 word2 n
## <chr> <chr> <int>
## 1 sir thomas 287
## 2 miss crawford 215
## 3 captain wentworth 170
## 4 miss woodhouse 162
## 5 frank churchill 132
## 6 lady russell 118
## 7 lady bertram 114
## 8 sir walter 113
## 9 miss fairfax 109
## 10 colonel brandon 108
## # ... with 33,411 more rowsgo back to bi-grams
bigrams_united <- bigrams_filtered %>%
unite(bigram, word1, word2, sep = " ")
bigrams_united
## # A tibble: 44,784 x 2
## book bigram
## <fct> <chr>
## 1 Sense & Sensibility jane austen
## 2 Sense & Sensibility austen 1811
## 3 Sense & Sensibility 1811 chapter
## 4 Sense & Sensibility chapter 1
## 5 Sense & Sensibility norland park
## 6 Sense & Sensibility surrounding acquaintance
## 7 Sense & Sensibility late owner
## 8 Sense & Sensibility advanced age
## 9 Sense & Sensibility constant companion
## 10 Sense & Sensibility happened ten
## # ... with 44,774 more rowsAnalyzing bi-grams
bigrams_filtered %>%
filter(word2 == "street") %>%
count(book, word1, sort = TRUE)
## # A tibble: 34 x 3
## book word1 n
## <fct> <chr> <int>
## 1 Sense & Sensibility berkeley 16
## 2 Sense & Sensibility harley 16
## 3 Northanger Abbey pulteney 14
## 4 Northanger Abbey milsom 11
## 5 Mansfield Park wimpole 10
## 6 Pride & Prejudice gracechurch 9
## 7 Sense & Sensibility conduit 6
## 8 Sense & Sensibility bond 5
## 9 Persuasion milsom 5
## 10 Persuasion rivers 4
## # ... with 24 more rowsbigram_tf_idf <- bigrams_united %>%
count(book, bigram) %>%
bind_tf_idf(bigram, book, n) %>%
arrange(desc(tf_idf))
bigram_tf_idf
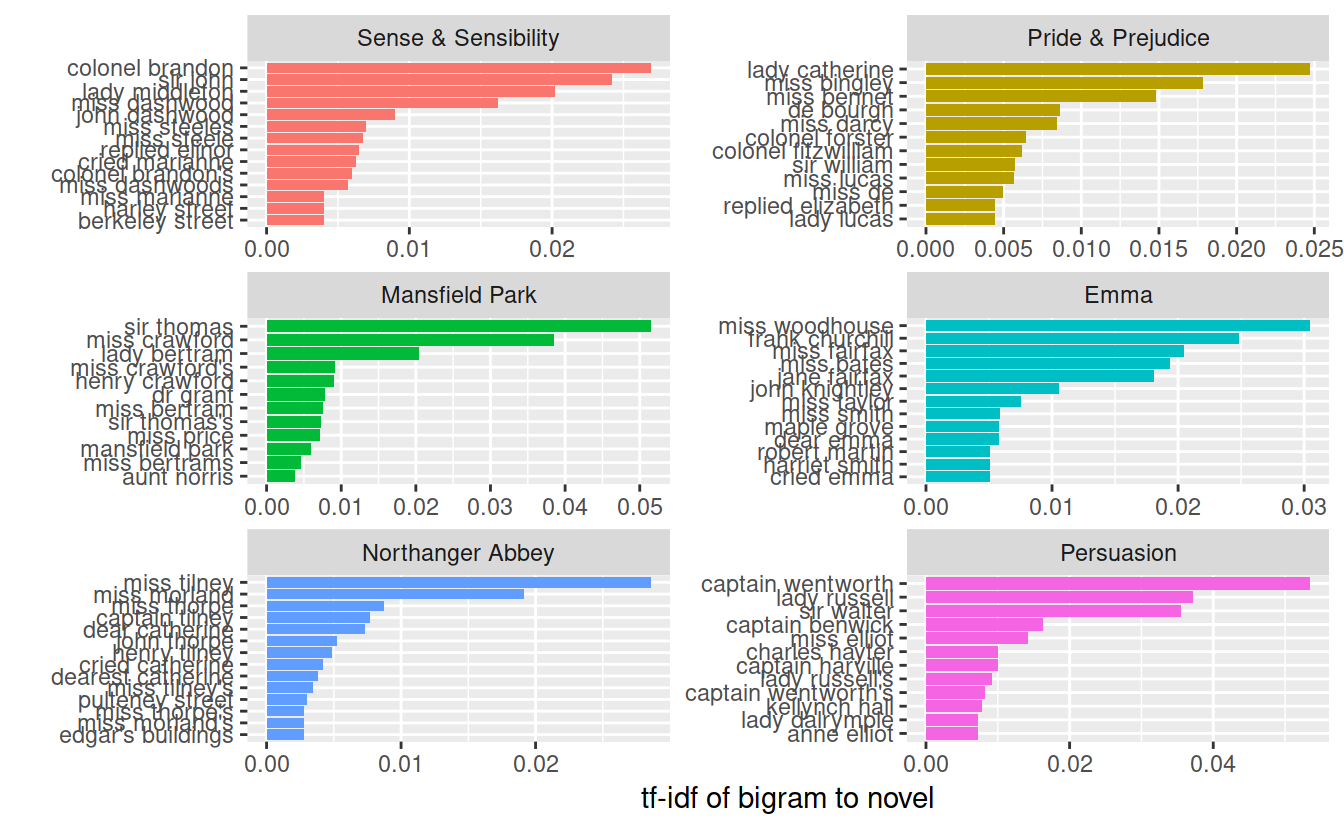
## # A tibble: 36,217 x 6
## book bigram n tf idf tf_idf
## <fct> <chr> <int> <dbl> <dbl> <dbl>
## 1 Persuasion captain wentworth 170 0.0299 1.79 0.0535
## 2 Mansfield Park sir thomas 287 0.0287 1.79 0.0515
## 3 Mansfield Park miss crawford 215 0.0215 1.79 0.0386
## 4 Persuasion lady russell 118 0.0207 1.79 0.0371
## 5 Persuasion sir walter 113 0.0198 1.79 0.0356
## 6 Emma miss woodhouse 162 0.0170 1.79 0.0305
## 7 Northanger Abbey miss tilney 82 0.0159 1.79 0.0286
## 8 Sense & Sensibility colonel brandon 108 0.0150 1.79 0.0269
## 9 Emma frank churchill 132 0.0139 1.79 0.0248
## 10 Pride & Prejudice lady catherine 100 0.0138 1.79 0.0247
## # ... with 36,207 more rowslibrary(ggplot2)
bigram_tf_idf %>%
arrange(desc(tf_idf)) %>%
group_by(book) %>%
top_n(12, tf_idf) %>%
ungroup() %>%
mutate(bigram = reorder(bigram, tf_idf)) %>%
ggplot(aes(bigram, tf_idf, fill = book)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ book, ncol = 2, scales = "free") +
coord_flip() +
labs(y = "tf-idf of bigram to novel",
x = "")