24.6 tf-idf: Term frequency, inverse document frequency
what a document is about by looking at the words.
tf-idf: measure how important a word is to a document in a collection (or corpus) of documents
library(dplyr)
library(janeaustenr)
library(tidytext)
book_words <- austen_books() %>%
unnest_tokens(word, text) %>%
count(book, word, sort = TRUE) %>%
ungroup()
total_words <- book_words %>%
group_by(book) %>%
summarize(total = sum(n))
book_words <- left_join(book_words, total_words)
## Joining, by = "book"
book_words
## # A tibble: 40,379 x 4
## book word n total
## <fct> <chr> <int> <int>
## 1 Mansfield Park the 6206 160460
## 2 Mansfield Park to 5475 160460
## 3 Mansfield Park and 5438 160460
## 4 Emma to 5239 160996
## 5 Emma the 5201 160996
## 6 Emma and 4896 160996
## 7 Mansfield Park of 4778 160460
## 8 Pride & Prejudice the 4331 122204
## 9 Emma of 4291 160996
## 10 Pride & Prejudice to 4162 122204
## # ... with 40,369 more rowsTerm frequency (standarized)
library(ggplot2)
ggplot(book_words, aes(n/total, fill = book)) +
geom_histogram(show.legend = FALSE) +
xlim(NA, 0.0009) +
facet_wrap(~book, ncol = 2, scales = "free_y")
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## Warning: Removed 896 rows containing non-finite values (stat_bin).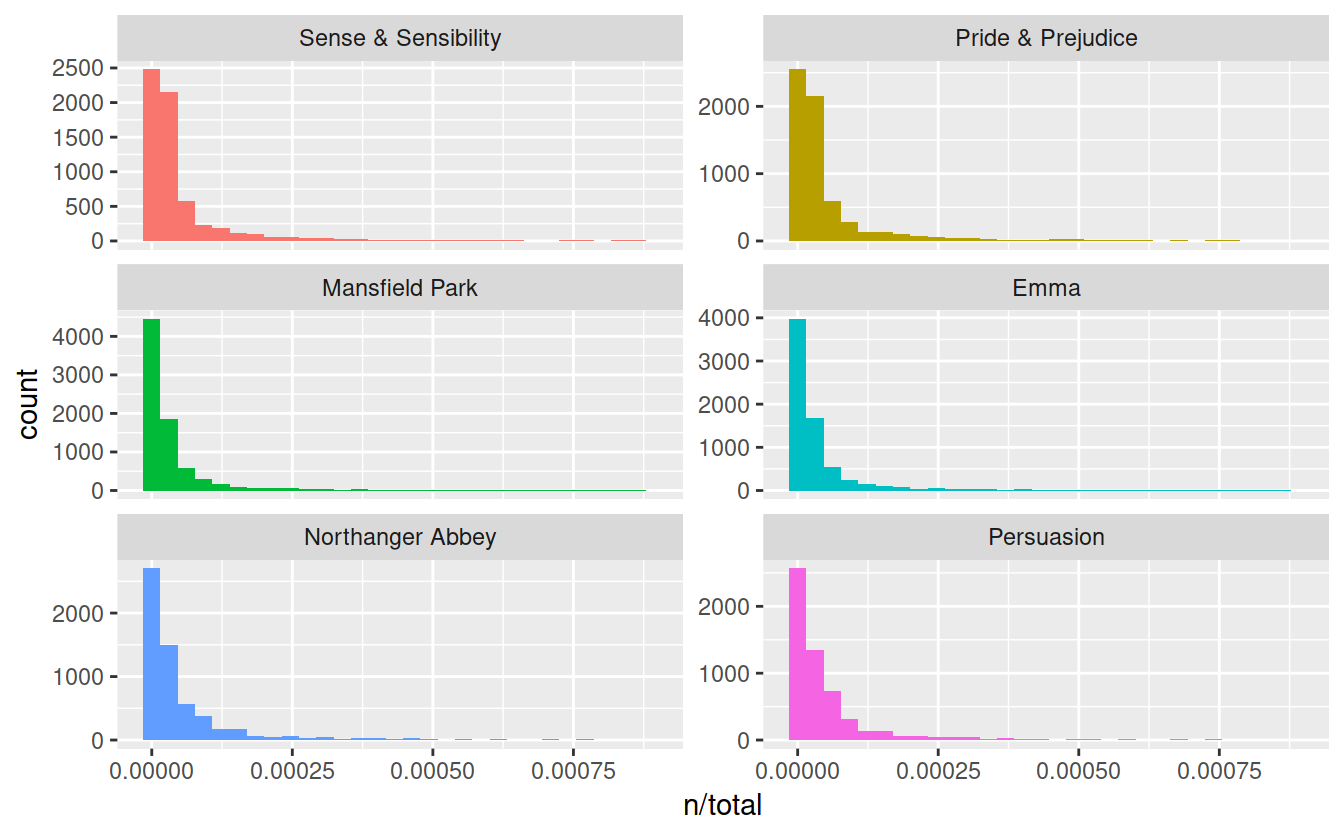
Zipf’s law states that the frequency that a word appears is inversely proportional to its rank.
find the important words for the content of each document by decreasing the weight for commonly used words and increasing the weight for words that are not used very much in a collection or corpus of documents